Sequence to Sequence Learning
Sequence to Sequence Learning이란?
- Seq2Seq Paper
1409.3215v3.pdf
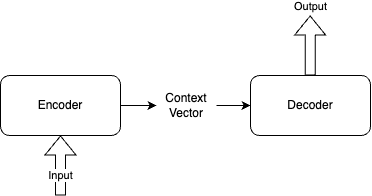
- Seq2Seq(Sequence-to-Sequence) 모델은 Input 데이터를 모델을 통해 다른 Output으로 변환하는 작업을 수행하는 DeepLearning 모델 혹은 Framework을 의미한다.
- 그림과 같이 모델에는 인코더(Encoder)와 디코더(Decoder)를 가지고 있다.
Context Vector의 경우, Encoder의 마지막 hidden Layer의 vector를 Decoder에 전달해주는 역할을 한다.
이러한 경우, Input의 마지막 쪽으로 가면서 앞쪽 input의 영향이 적어지는 Short-Term Memory 단점도 있다.
S2S Encoder
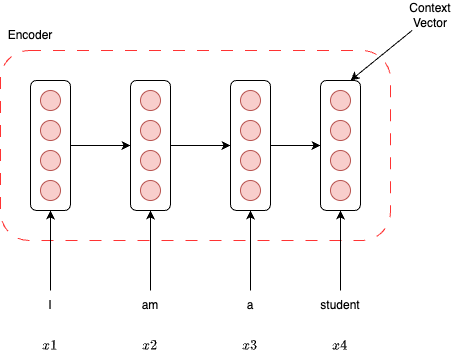
- Encoder는 원래의 문장 (그림에서는 “I am a student”)을 컴퓨터가 이해할 수 있도록 바꾸는 과정을 의미한다.
- Encoder RNN은 Context Vector를 뽑기 위해 one of encoding(차수가 클때는 낭비)을 사용한다.
- input token $x_1,\cdots,x_T$에 대하여 매 시간 “T”마다 one of vector(word vector)를 사용하며, Context vector C는 T시점에서의 RNN의 hidden state, 즉 $h_T$(Encoder time)가 있다.
- Encoder는 입력 시퀀스의 각 단어를 sequential하게 처리하면서 각 단계에서 hidden state를 업데이트하고, 최종적으로 전체 입력 시퀀스를 대표하는 고정 길이의 벡터(Context Vector)를 생성한다.
S2S Decoder